
[Python] 모두의 딥러닝 - 03. 신경망의 이해[오차 역전파]
Updated:
모두의 딥러닝 교재를 토대로 공부한 내용입니다.
실습과정에서 필요에 따라 코드나 이론에 대한 추가, 수정사항이 있습니다.
기본 세팅
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
mpl.rc('font', family='NanumGothic') # 폰트 설정
mpl.rc('axes', unicode_minus=False) # 유니코드에서 음수 부호 설정
# 차트 스타일 설정
sns.set(font="NanumGothic", rc={"axes.unicode_minus":False}, style='darkgrid')
plt.rc("figure", figsize=(10,8))
warnings.filterwarnings("ignore")
8. 오차 역전파
앞서 퍼셉트론 포스팅에서 단일 퍼셉트론으로 해결되지 않던 문제를 신경망(다층 퍼셉트론)으로 해결하였다.
다만 이때 XOR 문제를 해결하면서 이미 가중치와 바이어스에 대한 정답을 알고 코드를 구현했었다.
실제에선 입력 값과 출력 값만 알고 있을 때 이를 만족하는 가중치와 바이어스는 경사하강법을 이용해서 구한다.
오차 역전파 과정은 다음과 같다.
-
임의의 초기 가중치($W$)를 준 뒤 결과($y_{out}$)를 계산한다.
-
계산 결과와 우리가 원하는 값 사이의 오차를 구한다.
-
경사 하강법을 이용해 바로 앞 가중치를 오차가 작아지는 방향으로 업데이트한다.
-
위 과정을 더 이상 오차가 줄어들지 않을 때까지 반복한다.
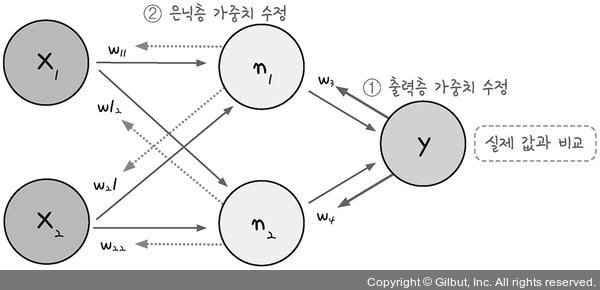
출처: https://thebook.io/080228/part03/ch08/01-01/
가중치와 바이어스의 최적화 과정이 출력층에서부터 시작해 앞으로 진행된다.
이로 인해 다층 퍼셉트론에서의 최적화 과정을 오차 역전파라고 부른다.
8.1 오차 역전파 계산법
오차 역전파 역시 경사하강법으로 가중치를 업데이트 하므로 다음과 같이 표현할 수 있다.
\[W(t+1) = W(t) - \dfrac{\partial E}{\partial W}\]-
$W(t+1)$: 새 가중치
-
$W(t)$: 현 가중치
-
$E$: 오차
여기서, 실제로 구해야하는 값은 가중치로 오차를 미분한 값인 $\dfrac{\partial E}{\partial W}$이다.
(그동안 배운 경사하강법과 달리 학습률이 없는데 아마 생략된게 아닐까 싶다.)
계산전에 먼저 기본 Notation은 다음 그림을 따르도록 한다.
다만 밑에 나올 공식들의 Notation은 개인적으로 이해하기 좋게 기입하였다.
참고로 아래 내용들은 심화 내용이므로 넘어가도 무방하다.
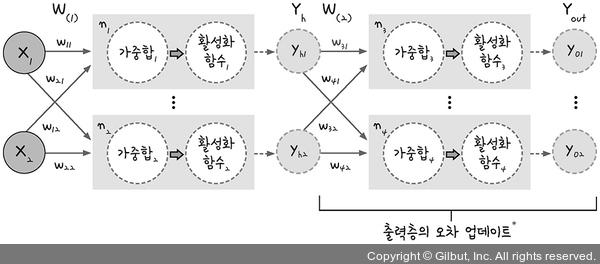
출처: https://thebook.io/080228/part06/01/01/
8.1.1 오차 공식
오차 $E$는 각 출력 값의 오차를 더한 값이며, 현재는 출력 값이 2개이므로 다음과 같이 표현 가능하다.
\[E = E_{1} + E_{2} = \dfrac{1}{2}(y_{t1} - y_{o1})^2 + \dfrac{1}{2}(y_{t2} - y_{o2})^2\]-
$y_{t1}, y_{t2}$: 실제 값
-
$y_{o1}, y_{o2}$: 가중치를 업데이트 하면서 바뀌게 되는 출력 값(편의상 관측값이라 하겠다.)
-
각 오차는 평균 제곱 오차를 이용해 구하였다.
8.1.2 출력층 가중치
우선 출력층으로 전달될 때 사용하는 가중치 중 $w_{31}$로 오차 $E$를 편미분 해보자.
체인 룰에 따라 다음과 같이 계산 가능하다.
\[\dfrac{\partial E}{\partial w_{31}} = \dfrac{\partial E}{\partial y_{o1}} \cdot \dfrac{\partial y_{o1}}{\partial n_{3}} \cdot \dfrac{\partial n_{3}}{\partial w_{31}} = (1) \cdot (2) \cdot (3)\]편미분이므로 식 (1)은 간단하게 다음과 같이 구할 수 있다.
\[\dfrac{\partial E}{\partial y_{o1}} = (y_{o1} - y_{t1})\]식 (2)를 구하기 전에 $y_{o1} = \sigma (n_3)$ 임을 기억하자.
즉, $y_{o1}$은 활성화 함수($\sigma$)에 $n_{3}$를 넣었을 때의 값이므로 식(2)는 활성화 함수의 미분이다.
활성화 함수를 시그모이드 함수라고 하자.
\[\sigma (x) = \dfrac{1}{1 + e^{-x}}\]시그모이드 함수의 미분 결과는 다음과 같다.
\[\dfrac{\partial \sigma (x)}{\partial x} = \sigma (x)(1 - \sigma (x))\]따라서, 식 (2)는 다음과 같다.
\[\dfrac{\partial y_{o1}}{\partial n_{3}} = \sigma (n_{3}) (1 - \sigma (n_{3})) = y_{o1} (1 - y_{o1})\]식 (3)을 구하기 전에 $n_{3} = w_{31}y_{h1} + w_{32}y_{h2} + 1$ 임을 기억하자.
여기서, 신경망에서는 바이어스를 항상 1로 설정한다.
바이어스는 그래프를 좌우로 움직이는 역할을 하는데, 활성화 함수인 시그모이드 함수가 가장 안정된 예측을 하는 바이어스가 1이기 때문이다.
식 (3)은 간단하게 다음과 같이 계산된다.
\[\dfrac{\partial n_{3}}{\partial w_{31}} = y_{h1}\]이를 종합하면 다음과 같다.
\[\dfrac{\partial E}{\partial w_{31}} = (y_{o1} - y_{t1}) y_{o1} (1 - y_{o1}) y_{h1}\]여기서, $(y_{o1} - y_{t1}) y_{o1} (1 - y_{o1})$를 $\delta y_{o1}$이라 하면 다음과 같이 표현 가능하다.
\[\dfrac{\partial E}{\partial w_{31}} = \delta y_{o1} y_{h1}\]이를 이용하면 가중치의 업데이트는 다음과 같은 식으로 구할 수 있다.
\[w_{31}(t+1) = w_{31}(t) - \delta y_{o1} y_{h1}\]8.1.3 은닉층 가중치
은닉층으로 전달될 때 사용하는 가중치 중 $w_{11}$로 오차 $E$를 편미분 해보자.
체인 룰에 따라 다음과 같이 계산 가능하다.
\[\dfrac{\partial E}{\partial w_{11}} = \dfrac{\partial E}{\partial y_{h1}} \cdot \dfrac{\partial y_{h1}}{\partial n_{1}} \cdot \dfrac{\partial n_{1}}{\partial w_{11}} = (4) \cdot (5) \cdot (6)\]식 (5)와 (6)는 앞서 (2)와 (3)을 구하는 과정과 동일하다.
\[\dfrac{\partial y_{h1}}{\partial n_{1}} = \sigma (n_{1}) (1 - \sigma (n_{1})) = y_{h1} (1 - y_{h1})\] \[\dfrac{\partial n_{1}}{\partial w_{11}} = x_{1}\]식 (4)는 출력층 가중치에서와 달리 $y_{h1}$이 $E_{1}, E_{2}$ 모두와 관련있어 복잡하다.
다음과 같이 분해 해보자.
\[\dfrac{\partial E}{\partial y_{h1}} = \dfrac{\partial (E_{1} + E_{2})}{\partial y_{h1}} = \dfrac{\partial E_{1}}{\partial y_{h1}} + \dfrac{\partial E_{2}}{\partial y_{h1}} = (7) + (8)\]식 (7)은 다시 다음과 같이 분해 가능하다.
\[\dfrac{\partial E_{1}}{\partial y_{h1}} = \dfrac{\partial E_{1}}{\partial y_{o1}} \cdot \dfrac{\partial y_{o1}}{\partial n_{3}} \cdot \dfrac{\partial n_{3}}{\partial y_{h1}} = (9) \cdot (10) \cdot (11)\]식 (9), (10)은 앞서 (1), (2)를 구하는 과정과 동일하며, 식 (11)은 (3)의 역수이다.
따라서 다음과 같이 표현 가능하다.
\[\dfrac{\partial E_{1}}{\partial y_{h1}} = (y_{o1} - y_{t1}) y_{o1} (1 - y_{o1}) w_{31} = \delta y_{o1} w_{31}\]식 (8) 역시 같은 과정으로 계산하면 다음과 같다.
\[\dfrac{\partial E_{2}}{\partial y_{h1}} = (y_{o2} - y_{t2}) y_{o2} (1 - y_{o2}) w_{41} = \delta y_{o2} w_{41}\]종합하면 최종 결과는 다음과 같다.
\[\dfrac{\partial E}{\partial w_{11}} = (\delta y_{o1} w_{31} + \delta y_{o2} w_{41}) y_{h1} (1 - y_{h1}) x_{1}\]여기서, $(\delta y_{o1} w_{31} + \delta y_{o2} w_{41}) y_{h1} (1 - y_{h1})$를 $\delta h_{1}$이라 하면 다음과 같이 표현 가능하다.
\[\dfrac{\partial E}{\partial w_{11}} = \delta h_{1} x_{1}\]이를 이용하면 가중치의 업데이트는 다음과 같은 식으로 구할 수 있다.
\[w_{11}(t+1) = w_{11}(t) - \delta h_{1} x_{1}\]8.1.4 델타식
앞서 살펴본 과정을 정리해보자.
-
출력층 오차 미분 업데이트: $(y_{o1} - y_{t1}) y_{o1} (1 - y_{o1}) y_{h1} = \delta y_{o1} y_{h1}$
-
은닉층 오차 미분 업데이트: $(\delta y_{o1} w_{31} + \delta y_{o2} w_{41}) y_{h1} (1 - y_{h1}) x_{1} = \delta h_{1} x_{1}$
각 델타식은 모두 오차 $\cdot$ 관측값 $\cdot$ (1 - 관측값) 형태를 띄고 있다.
은닉층의 경우 직관적인 오차 형태가 아니지만 형태가 복잡할 뿐 오차를 나타낸다.
델타 식이 중요한 이유는 층을 거슬러 올라갈 때마다 같은 형태가 나오기 때문이다.
이를 알고 있으면 코딩으로 설계하기에도 용이할 것이다.
8.2 오차 역전파 구현
오차 역전파를 이용해 XOR 문제를 해결할 가중치를 구해보자.
아래는 심화학습이므로 넘어가도 무방하다.
코드를 하나하나 뜯어보다가 모멘텀 SGD 등 아직 모르는 개념 때문에 소스코드를 그냥 실행만 해보았다.
코드에선 활성화 함수를 달리 사용하고 학습률도 적용해준다.
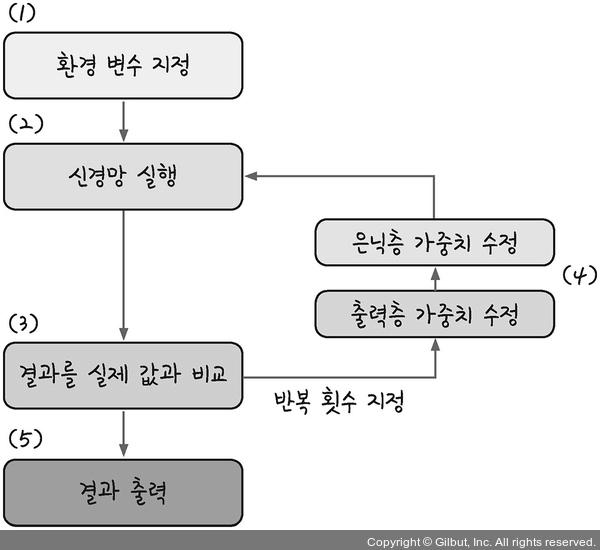
출처: https://thebook.io/080228/part03/ch08/02/
# -*- coding: utf-8 -*-
import random
import numpy as np
random.seed(777)
# 환경 변수 지정
# 입력값 및 타겟값
data = [
[[0, 0], [0]],
[[0, 1], [1]],
[[1, 0], [1]],
[[1, 1], [0]]
]
# 실행 횟수(iterations), 학습률(lr), 모멘텀 계수(mo) 설정
iterations=5000
lr=0.1
mo=0.4
# 활성화 함수 - 1. 시그모이드
# 미분할 때와 아닐 때의 각각의 값
def sigmoid(x, derivative=False):
if (derivative == True):
return x * (1 - x)
return 1 / (1 + np.exp(-x))
# 활성화 함수 - 2. tanh
# tanh 함수의 미분은 1 - (활성화 함수 출력의 제곱)
def tanh(x, derivative=False):
if (derivative == True):
return 1 - x ** 2
return np.tanh(x)
# 가중치 배열 만드는 함수
def makeMatrix(i, j, fill=0.0):
mat = []
for i in range(i):
mat.append([fill] * j)
return mat
# 신경망의 실행
class NeuralNetwork:
# 초깃값의 지정
def __init__(self, num_x, num_yh, num_yo, bias=1):
# 입력값(num_x), 은닉층 초깃값(num_yh), 출력층 초깃값(num_yo), 바이어스
self.num_x = num_x + bias # 바이어스는 1로 지정(본문 참조)
self.num_yh = num_yh
self.num_yo = num_yo
# 활성화 함수 초깃값
self.activation_input = [1.0] * self.num_x
self.activation_hidden = [1.0] * self.num_yh
self.activation_out = [1.0] * self.num_yo
# 가중치 입력 초깃값
self.weight_in = makeMatrix(self.num_x, self.num_yh)
for i in range(self.num_x):
for j in range(self.num_yh):
self.weight_in[i][j] = random.random()
# 가중치 출력 초깃값
self.weight_out = makeMatrix(self.num_yh, self.num_yo)
for j in range(self.num_yh):
for k in range(self.num_yo):
self.weight_out[j][k] = random.random()
# 모멘텀 SGD를 위한 이전 가중치 초깃값
self.gradient_in = makeMatrix(self.num_x, self.num_yh)
self.gradient_out = makeMatrix(self.num_yh, self.num_yo)
# 업데이트 함수
def update(self, inputs):
# 입력 레이어의 활성화 함수
for i in range(self.num_x - 1):
self.activation_input[i] = inputs[i]
# 은닉층의 활성화 함수
for j in range(self.num_yh):
sum = 0.0
for i in range(self.num_x):
sum = sum + self.activation_input[i] * self.weight_in[i][j]
# 시그모이드와 tanh 중에서 활성화 함수 선택
self.activation_hidden[j] = tanh(sum, False)
# 출력층의 활성화 함수
for k in range(self.num_yo):
sum = 0.0
for j in range(self.num_yh):
sum = sum + self.activation_hidden[j] * self.weight_out[j][k]
# 시그모이드와 tanh 중에서 활성화 함수 선택
self.activation_out[k] = tanh(sum, False)
return self.activation_out[:]
# 역전파의 실행
def backPropagate(self, targets):
# 델타 출력 계산
output_deltas = [0.0] * self.num_yo
for k in range(self.num_yo):
error = targets[k] - self.activation_out[k]
# 시그모이드와 tanh 중에서 활성화 함수 선택, 미분 적용
output_deltas[k] = tanh(self.activation_out[k], True) * error
# 은닉 노드의 오차 함수
hidden_deltas = [0.0] * self.num_yh
for j in range(self.num_yh):
error = 0.0
for k in range(self.num_yo):
error = error + output_deltas[k] * self.weight_out[j][k]
# 시그모이드와 tanh 중에서 활성화 함수 선택, 미분 적용
hidden_deltas[j] = tanh(self.activation_hidden[j], True) * error
# 출력 가중치 업데이트
for j in range(self.num_yh):
for k in range(self.num_yo):
gradient = output_deltas[k] * self.activation_hidden[j]
v = mo * self.gradient_out[j][k] - lr * gradient
self.weight_out[j][k] += v
self.gradient_out[j][k] = gradient
# 입력 가중치 업데이트
for i in range(self.num_x):
for j in range(self.num_yh):
gradient = hidden_deltas[j] * self.activation_input[i]
v = mo*self.gradient_in[i][j] - lr * gradient
self.weight_in[i][j] += v
self.gradient_in[i][j] = gradient
# 오차의 계산(최소 제곱법)
error = 0.0
for k in range(len(targets)):
error = error + 0.5 * (targets[k] - self.activation_out[k]) ** 2
return error
# 학습 실행
def train(self, patterns):
for i in range(iterations):
error = 0.0
for p in patterns:
inputs = p[0]
targets = p[1]
self.update(inputs)
error = error + self.backPropagate(targets)
if i % 500 == 0:
print('error: %-.5f' % error)
# 결괏값 출력
def result(self, patterns):
for p in patterns:
print('Input: %s, Predict: %s' % (p[0], self.update(p[0])))
if __name__ == '__main__':
# 두 개의 입력 값, 두 개의 레이어, 하나의 출력 값을 갖도록 설정
n = NeuralNetwork(2, 2, 1)
# 학습 실행
n.train(data)
# 결괏값 출력
n.result(data)
# Reference: http://arctrix.com/nas/python/bpnn.py (Neil Schemenauer)
error: 0.66537
error: 0.00263
error: 0.00088
error: 0.00051
error: 0.00036
error: 0.00027
error: 0.00022
error: 0.00018
error: 0.00016
error: 0.00014
Input: [0, 0], Predict: [0.0006183430577843577]
Input: [0, 1], Predict: [0.9889696478602484]
Input: [1, 0], Predict: [0.9889970505963889]
Input: [1, 1], Predict: [0.0021449252379778148]
- 결과를 보면 예측 값이 실제 값과 유사하여 XOR 게이트를 만드는 가중치를 잘 찾았다.
Leave a comment